I’ve been seeing a lot lately about Advent of Code. I didn’t really want to do this because it’s a big time suck but I (mistakenly, probably) looked at the first one and thought “well some does most of the work for this one…” and now I’m stuck.
I’m starting a few days late and we’ll see how much energy I have going forward but we’ll put up my solutions here.
The biggest problem is my brain won’t allow me to stop these to the exclusion of everything else (eating, sleeping, etc.). Even if I solve it I still spend time iterating on it.
I don’t have any rules going in but I am using babashka so I guess I’m limited to whatever subset of regular clojure it provides.
First I need a predicate function, digit? that take a character and returns an integer if it is a digit and nil otherwise.
The extract-calibration-code function takes an alphanumeric string and returns a two digit integer. The 10s place is the result of (some digit? s) which will return the first digit and the ones place is the same on the reversed s to get the last digit.
To bring it together we get the supplied input file and create a sequence of lines of alphanumeric strings from it called codes. Finally, we reduce + on a map of extract-calibration-code against each string to add up all the two digit numbers.
This was a two-parter. They didn’t reveal the second part until after you finished the first one so rather than rewrite it properly I hacked in an atom to get the second result.
I’d never used named matching groups before (I didn’t even know about them) so I worked them in. I have game and runs named for easy extraction.
The key to this one was when I realized that I didn’t need to worry about splitting out the runs. I just needed to find the max number for each color. You can see that where I split the runs group using both ; and ,.
The reduce function does the heavy lifting here. I extract the color (c) and associated number (n). I start with an empty map of the three colors with 0 and assoc in the max value for whatever color comes up in the sequence. That map comes out as max-cubes-map.
I then have a big ol’ if with three and conditions to check that the max values are in range. If so, we return the game number, otherwise zero.
The final aoc2 function grabs the input file and then sums up all the possible games.
The power var is from the aforementioned second part. I get it by multiplying the three max values. I then swap! it into my total-power atom adding it to whatever is already there.
The return from aoc2 is a map with the sum and the final value of the total-power atom.
This one took me too long and I should probably implement it differently. It had a part 2 which I didn’t do but gave me a clue as to a maybe better way to do it. I might reimplement later but I need to press on.
The wazzit function uses the digit function from my day 1 solution. It just converts all the characters into either :symbol, :dot, or a digit. Not strictly necessary but it made things cleaner in my mind.
The general approach was to use the partition function to assemble “windows” of rows and columns. Each row of the input schematic then has a previous row and a next row. Also each character within a row has a previous and next character. To do this, you need to add rows to the top and bottom of the entire array and columns before and after. I convert everything to vectors since we need indexed lookup to these arrays.
We then process each row in a doseq, construct the column windows for the row and process each column window through a cond statement.
We have an atom that holds an accumulated total and a few state variables. If the cond encounters a digit, it checks for adjacency to a symbol using the symbol-adjacent? function. If it finds a symbol it starts to collect digits in the :current-num key of the atom. When a non-digit is encountered, the number is created, added to the total, and the state flags are reset.
The alternate approach would be to progress through the arrays looking for symbols instead of digits. When you encounter a symbol, you call some function that collects all the adjacent positions and filters out the digits. Then, for each digit, you have a second function that checks left and right for more digits until it gets the entire number. You’d have to have a state variable that holds a set of the positions you have checked that have digits so that you don’t grab a number more than once. This implementation would make it fairly easy to complete part 2 of the challenge.
The part one was super easy along with some regular expression stuff. I decided to use clojure transducers to do the main work. It’s a good use for them because you have several discreet steps to do with each card.
Do all the parsing of the text line to get the winning numbers and picks
Calculate the intersection of the two sets
Assign point values to the count of the intersection set
That process-card function has some repetition that could be factored out. Deal with it!
It’s a nice, modular approach.
It seems that there is always a part 2 though. This one was a bit tricky. I solved it with a bit of recursion.
I reuse the parsing transducer (nice) but I use a different one to assemble a map that has a key for each card and the number of matches as a value. This is the raw data for calculating how many copies are propagated.
I create a state atom to hold a map showing how many copies get added for each card. Notice I put in a bunch of printlns to track things. That was very helpful during the debugging.
We first add a copy for the original card with a swap!, then loop through, distributing matches to the cards down the line. Once it is done, we add up all the values in the state map.
I got tripped up by the fact that I was assuming my match-counts map would have its keys in card order. That is not to be assumed so I needed to convert it into a sorted map.
Advent of Code Day 5 - If you give a seed a fertilizer
This one was very frustrating for reasons that had nothing to do with coding the solution. I had it done pretty early yesterday and it worked fine with the test data. It worked to completion on the input data and works in 0.06 seconds. But the returned answer was the wrong one. This is the nightmare scenario for these puzzles because there isn’t much you can do.
So I spent a bunch of time trying to figure out if I was parsing the input wrong or if I had some mistyped somewhere. Couldn’t find it before bedtime. I really liked the aesthetics of this solution though so I was going to post it here anyway. I was cleaning it up, removing some of the instrumentation I had put in. When it was all cleaned up I ran it again and the result was different. Of course, I submitted that value and it was the correct one. I don’t really know what changed to make it work.
I had originally coded up something that assembled a hashmap for each almanac and got it working with the test data without first looking at the input data. Then when I got my first look at it
It took half a second to realize my hashmaps weren’t going to get assembled this century. I saw in some message boards that people were trying to “brute force” a solution to this. Maybe, but I didn’t want to melt my CPU.
The almanac-get is modeled on the regular clojure get function which takes a map and a key and returns the value for that key.
Instead of looking for the key, we call a get-src->dest-triplet function which filters through the specified almanac map looking for a source range (as determined by the mapped? predicate. If it finds one, it returns the almanac triplet (or nil if there is none) and the almanac-get function calculates the destination value from that triplet.
The filter in that get-src->dest-triplet should only return one or zero triplets but I put a println in there to catch if there was more than one. There wasn’t.
A way to improve the efficiency would be to do a binary search of the almanac instead of doing a filter. You’d have to sort each almanac by the second element (sort-by second seed->soil, for example), but it already runs pretty darn fast so there is no point.
The location-from-seed function threads the lookups through the 7 almanacs and produces a location value. You then just need to reduce min the list of seeds to get the smallest one.
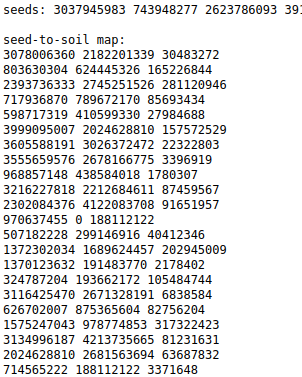
I have the test almanacs and seeds def’d here. To run the input data I include an external namespace with the same vars and aliased to aoc5.
I didn’t write a parser for the input data but I tried to make it as fool proof as possible. I copied the almanacs from the input and pasted directly into a clojure vector. Since no commas are needed, I didn’t need to do any other input grooming. I just ran (partition 3 seed->soil-raw) on them to create seed->soil.
I haven’t done part 2 yet because I want to move forward but I may go back to it later.
The part 1 took only a few minutes so I was suspicious that part 2 would present challenges. When looking at the problem I was thinking that it would be something like a Gaussian distribution when you plot distances traveled against times but I went ahead and brute-forced the results because there weren’t that many.
Once part 2 came up I saw that yes indeed they were going to make it hard by giving us huge numbers to work with. I tried to experiment with calculating the count of combinations with just one of the races to see if it would complete in any reasonable time. I killed it after 10 minutes. We were going to have to figure out the formula for the curve produced by the time/distance pairs.
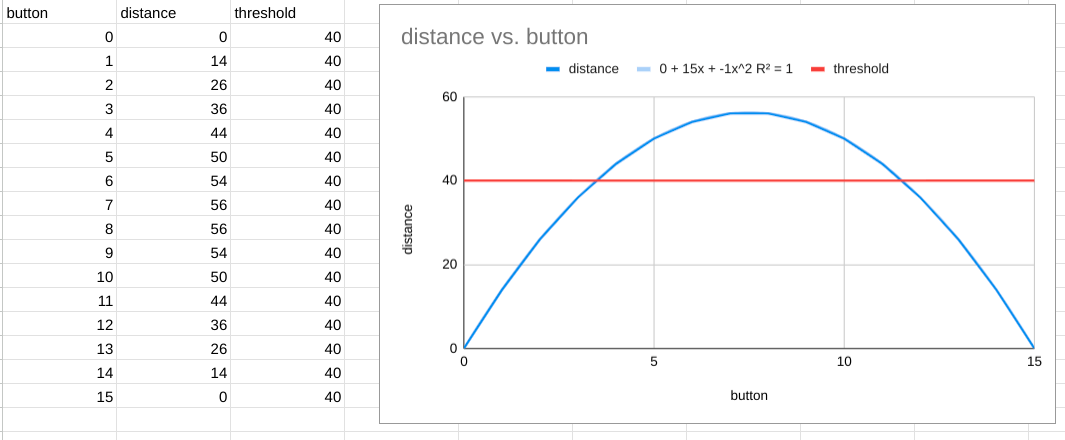
So I whipped up a spreadsheet and plotted the 15 40 race.
Notice that I was lazy and had gogle sheets add a trend fit equation for the blue curve so it would show me the exact polynomial I needed.
At that point I realized that it’s not a Gaussian distribution, it’s just a plain old polynomial of second order. That means I needed to dust off the old brain and recall the Quadratic Formula.
The distance-traveled function is just rate times time equals distance. The button-time is really just the rate.
The winning-button-pushes function is the brute force solution for part 1. It just calculates all the distances and filters all the ones above the duration threshold packaging it up as a sequence of two value vectors. It’s a bit hard to follow so I should have done it with a thread macro or transducers but since it wasn’t the real solution, I didn’t bother.
the aoc-1 function counts up the winning pairs returned and then multiplies them together to produce the final result.
To do the second part I created a quadratic-solver function. It is nothing but the quadratic formula expressed in lisp. I even used a, b, and c variables. The button-time parameter becomes b and -race-duration is c. We need to calculate both the plus and minus values so I’m mapping the equation across both the + and - functions to get a pair of solutions.
The aoc-2 function has to create the input button time and duration by jamming together the numbers in the input vectors.
The solutions are not integers so we get the ceiling of the first solution and the floor of the second one. We then calculate the return value by taking the difference and adding 1 since were zero-based.
This one was nice for learning the intricacies of sort-by. That will probably come in handy.
I’m representing a hand input as a two-vector of a string of labels and a bid. I first create maps to establish the order of the labels and then a map of the order of types. Each type is a keyword.
Every hand has a “fingerprint” which is defined a sorted vector of the frequencies of its cards. Each of the types has a unique fingerprint. The :three-of-a-kind type has 2 unique cards (1 and 1) and one group of 3 cards so its fingerprint is [1 1 3].
Since clojure has immutable data structures you can do things that are impossible or at least ill advised in other languages like make indexed lists into keys for a map. That’s what the fingerprint->type map is.
After wrestling around for a bit with representing hands and sorting a group of maps I decided to use a defrecord (Hand) with 4 fields. This simplified things in a way that I liked.
The Hand record has the original hand string, a type derived from a get-type function, an sortv which is a vector that converts the hand string into their corresponding numbers in the labels->order map, and finally the bid. Here is what a Hand looks like
The sort-handrecs function then looks pretty simple. The juxt call establishes the sorting levels; first by type and then by the pseudo-alphabetical order of the labels. Sorting the sortv values doesn’t require any special treatment but for the type you have to do a map lookup to find an order number for each Hand.
The calculate-winnings function multiplies each bid by the Hand’s rank order (which I had to reverse since the highest rank goes to the best hand). Add up the products and spit out the score.
For part 2 I constructed a table (on paper!) to show for each type what would be the optimal conversion of J to make the best hand. Here the fingerprints came in handy. You need to account for each unique number in each fingerprint (1 and 2 J’s for one-pair, 1 and 3 for three-of-a-kind etc. So if I have a three-of-a-kind and a 1 in the fingerprint is a joker, changing it to whatever the 3 card is promotes the hand to a four-of-a-kind.
The key insight that came from this exercise is that I didn’t need to mess at all with the hand string. I just needed a promote-hand function that assocs a new sortv vector and uses my promotion table to assoc the Hand’s type. That is what the condp call in promote-hand is doing. In one case (for two-pair) I had to care about how many jokers are in the hand. Plus, if there are no jokers, you don’t promote the hand at all. Here is the Hand from above in its promoted state.
The final piece was to create a different “jokers order” for the cards. I could have done this just by associng the part one map but having a separate map was easier and seemed clearer. You can see in my Hand representations above that all the sortv changes but they maintain their relative positions excepting the J turns from 3 to 12 so the sorting still comes out right.
The aoc-1 and aoc-2 functions are done with tranducer functions xf-make-hand and xf-promote-hand. My aoc-1 just uses the former xf and aoc-2comps them.
I have to admit I didn’t have a lot of motivation for this one. I find graph traversal problems to be tedious. It took me longer to get the energy to finish this one.
I looked at the input file first this time and chrome gave me a chuckle when it thought it was being helpful.
The workhorse function is follow-instruction. It takes the graph, which is a hashmap of a three-letter key and an array of two three-letters values for the left and right nodes. I converted the instructions list from Ls and Rs to 0 and 1 so that a get function will get the right value from the array. The function returns a vector of the key we are following based on the instruction and the array returned from the lookup of that key.
With that, the part 1 was pretty straightforward with some recursion. We turn the instruction list into an infinite cycle of itself and set up a state atom, cnt to keep track of how many steps we’ve run.
The loop variables are i, the current instruction, r, the rest of the instructions, and v, the result of a call to follow-instruction. It’s nice that in clojure, even though my instructions sequence is infinite, a call to (rest instructions) doesn’t cause problems. Laziness is nice here.
The loop gets the result of calling follow-instruction on i, it increments the count atom and then tests the result of the follow-instruction to see if it is ZZZ. If it is, we output the value of cnt and we’re done.
If not, we recur with the next instruction the rest of the remaining list, and the new-v value.
For the second part, it would be possible in theory to just use the same procedure changing the v to a list of vs that are a result of mapping follow-instruction over all the keys that start with A. We’d just have to have a loop checker that looks for when all the resulting calls to follow-instruction end with Z.
I wrote this one but I found that it would stack overflow pretty quickly. So I changed the cnt atom to a state map and collected some data as it ran. I discovered after some playing around, that each of the 6 would appear in the result sequence and would appear regularly. This meant that we were dealing with a cycle for each Z key. Multiple cycles should eventually align, right?
I modified my state atom to store the count when it first appeared and got the cycle number for each Z key after only about 90,000 loops.
I then had to look up how to get the Least Common Multiple for all the numbers. There is an LCM spreadsheet formula in Excel and Sheets. I plugged it in and it came up with the correct answer.
For completeness, I altered my clojure code to calculate the LCM. I had ChatGPT write that function for me. I didn’t get the lcm function right but it was easily fixed.
Some problems (like Day 3, I think) are best tackled with a more imperative approach, but problems like day 9 are where a functional language really shines.
The main work is done by the calc-diferences function. It takes a line of input, divides it into a sequence of two values and applies the - (difference) function to each of them. This produces the next line.
The extrapolated-list function is a recursive loop that accumulates the differences lines until it gets to a line where all the values are the same. I test that by turning a line into a set and counting its members. Also, there is no need to go to the last line of all zeros because it doesn’t add anything to the final result. The extrapolated-list returns the triangular shaped lists in the instructions.
The next-value function takes a line of input and reduces a sum of the extrapolated list (reversed since we start at the bottom). It grabs the last value and adds them all up.
The final result for part 1 just reduces the sum of all the lines in the report.
For part 2 we only need swap out the map across next-value with a map across a previous-value function. The previous-value function is similar to next-value in that reduces across a reversed extrapolated list, but the reduce function is different. Since subtraction is not commutative we need to reverse the order of the values in the subtraction.
Engineering software is largely a matter of managing tradeoffs. Time, money, efficiency, etc. For better or worse, I am very stubborn with respect to the tradeoff between doing something fast vs. doing something “right”. I had that problem with this challenge. I thought of an approach that I really liked and thought was “right”, but it took me a long time to execute it properly.
There’s no real time pressure here. I don’t have to finish any of these but of course, there is always a new puzzle coming in 24 hours so you want to get done. In the end, I’m glad I took the extra time because it was a valuable learning experience. That’s the most important thing, right? I did decide to forego the second part of this one in the interest of time. I have an approach for that, but it will take some time to execute and I’ll try to return later.
First things first, I understand why the represented the mazes the way they did with characters J, F7 etc, but that is what the box characters are for. I spent too much time converting the map but it looks a lot nicer
We first create for navigation functions (north, south, east, and west). They take a coordinate and return a new coordinate in the next location. We add a :from metadata element to the coordinate that identifies where the result came from. So east comes from west and north comes from south.
We then map the 7 characters in the input to two navigation functions. The | character maps to north and south and so on. We ignore the . character and put a value of :START for the S character.
The make-tilemap function parses the input and creates a hashmap that holds the coordinates of all the characters in the directions map. The keys are coordinates [x y] and the values are the two direction functions for that tile. Finally, we put a metadata item in the tilemap that allows us to locate the start position.
The get-start-directions function has two forms. The first takes a tilemap and a start coordinate. The other gets the start coordinate from the tilemap metadata. It determines which two direction functions apply to the start coordinate. We determine this with the points-back? function. This function navigates in each of the four directions from start and then navigates from each of those 4 new coordinates to their two associated directions. If one of them goes back to the start coordinate, we know it is connected to start.
Now we have a tilemap with a start coordinate located in its metadata and directions functions attached to each coordinate including start.
The navigate function does most of the work from here. There are two forms. They both take a tilemap and a tile or coordinate. It grabs the tile’s direction functions and removes a from function. This is so we don’t navigate back to where we just navigated to. One form of navigate lets you specify a from function explicitly and the other gets it from metadata on the coordinate. We then execute the direction function and return the new coordinate along with its :from metadata.
The last thing is to navigate the entire path from the start coordinate. This is done with a loop-recur. We create a path accumulator to hold the coordinates of the path and start off by navigating from the start coordinate. Then we check to see if the resulting coordinate is the same as the start. If not, we conj the coordinate to the path and navigate to the next coordinate.
The last last thing is to count the values in the path vector and divide by two to get the farthest distance.
We start with the input data. For whatever reason, I didn’t use the test data much (pocket-universe) and mostly just used the full dataset for the development.
The chart-universe function assembles a vector of vectors holding the data. The two-arity version only assembles the coordinates of the galaxies. The three-arity version allows a remove function which defaults to nil?. When you supply false, it will not remove anything and you’ll get the whole two-dimensional array. The full array is necessary to find the empty rows and columns.
The empty-space function gets the whole universe and returns a map listing all the empty rows and columns. To find the empty rows we just map-index across the universe and return the row numbers where every? nil? is true. To get the columns, we just transpose the universe with apply mapv vector and find the empty rows of the transposed array. This transpose operation was, by far, the most time-consuming thing.
To get the coordinates of all the galaxies, we use get-galaxies. It charts the universe and flattens the response and finally partition it into two number coordinates. There’s probably a better way to do that but this worked.
I did a quick and dirty get-combinations function which is a bit hacky. I would normally use the clojure combinatorics library but I didn’t have it available in babashka. It just takes a list of all the galaxy coordinates and produces a list of [[x1 y1] [x2 y2]] combinations.
To handle universe expansion I ignored the temptation to rewrite the universe map and just figured out how expansion affects any given coordinate (or pairs of coordinates). The expanded-distance function takes a pair of galaxy coordinates and the map of the empty rows and columns. Internally, it defines an expander-fn function. This function uses the coordinates to determine if the galaxy moves down or to the right based on how many blank rows or columns are to the left or above it. You count these up and add them to the x and y coordinates of the galaxy to determine its new position. We calculate new values for the 4 x and y coordinates and then add the differences to get the distance between them.
I noticed some people online puzzling over how to calculate the distance. I knew right away how to do it though. I think it’s because I’ve spent so many years running and walking on square blocks in the city. If you want to get from point A to point B, it doesn’t matter what path you take, it’s always the same number of blocks.
As I mentioned, part 2 was quite simple and took only the smallest modification to the expander function. I added an expansion-factor parameter to expanded-distance which multiplies that factor by the number of black rows/columns above/left of the coordinate. It was a bit tricky because you need to dec the expansion factor. So you multiply by 999 instead of 1000. This is because you already had one blank and you’re adding another 999 before you multiply.
When I first ran part 1 it was taking a long time. This had me puzzled. There are only 10^5 combinations to check so it should be fairly quick. When I took a closer look, I saw that I was calling the empty-space function with each combination. This function has the transposed universe and as I mentioned, this takes the most time so I was trying to transpose a hundred thousand times. I just moved it into the let form and everything went as smooth as the Cosmic Microwave Background from there.
Is there a more useful function than the clojure partition function? It has certainly been a workhorse in this set of Advent of Code problems. This was another one where I was able to do the second part pretty quickly because I implemented part 1 well, though I had a bit of repetition that I didn’t bother to factor out.
The search-for-reflection function has the main loop for the solution. It uses the aformentioned partition to grab two rows from the fields input. The partition steps by one so each element contains the current row and the upcoming row. The loop sets an accumulator to keep track of the rows we have visited.
The cond statement has three tests. The first checks to see if the two rows in the partition are the same (a simple equality in clojure). It also makes a call to a reflection? predicate function which passes whatever rows have been visited so far and a list of the remaining rows yet to be visited. If reflection? returns true we count the number of rows visited and increment it to return the score.
The second condition checks to see if there are any remaining rows to check. If there aren’t any rows left and we haven’t exited the loop yet that means there are no reflections so we return zero.
The third condition calls recur to start the loop again with the next values and conjing the current row to the list of rows visited.
I was tripped up a bit by the order of the condition functions. You need to check for equality first because if the matching pair is the last one the (empty rst) condition will be met even though there is a reflection and you’ll get an erroneous score of 0.
The reflection? predicate is pretty simple. We need to compare all the rows we’ve visited (in reverse order) with the rows yet to be checked. If all of them are equal, that means we have a reflection. A nice feature of the clojure language here is that we don’t have to worry if either of the input sequence of rows is longer than the other. The map function will automatically check only the shorter list, even if it is nil. Saves a lot of checks that I would have to do any other languages. [Side note, I was unaware that every? true? [] is true which is very convenient here.]
The aoc13-1 function maps a vector of a pair of search-for-reflection calls. One against the input field to look for row reflections and again against the transposed field to check for columns. We multiply the row score by 100 and then add everything up to get the final score.
Part 2 threw me for a bit. We certainly didn’t want to try flipping every cell on each field to check for reflections. After a minute or two I figured out that we just needed to redefined what equality means when comparing rows. In part 1 we just use the regular = function to compare rows. If one of the rows has a smudge they wouldn’t be = but if we define a new function smudge= then we can compare them however we want. The smudge= function here interleaves the two collections and partitions them into pairs. We compare each pair. The collections are smudge= if only one pair is unequal.
To search for smudged reflections we need to replace the condition function that checks for equality with two different conditions. The first checks to see if the the current and next rows are smudge=. If so, we call the same reflection? function as we did in part 1. The second condition checks for regular equality between the current and next row. If they are OG equal we look for smudged equality for the remaining rows.
The new smudged-reflection? function to is a bit more complicated. We need the check that there is exactly one smudge= pair of rows and all the others are OG equal. There is probably a better clojure way to do that than I did here but I’m doing it by mapping the rows visited rows and rows to come with both = and smudge=. I then make sure only one true appears in the smudge= map result and then map or over the pair to check that all the elements are either = or smudge= and that the smudge= pair is in the same place for both.
The aoc-2 function is the same as aoc-1 except that is uses the search-for-smudged-reflection function. Note that I never actually explicitly find which is the smudged cell. There is really no need. You only need to know that it exists and that there is only one.
When I read this one in the morning my first reaction was, “What’s the catch?” It seemed too easy. As it turned out though there was no catch. I did part one in about 5 minutes.
The feed-hash function hashes a single character. The hash-of function hashes an entire string. That is all that was needed to complete part 1.
For part 2 I opted to use a command pattern. The two commands are vectors with the first element being the type (:ADD or :REM). The remaining elements are parameters. This is similar to how clojure’s nrepl protocol works. We have a run-cmd function that dispatches the command vector to the appropriate implementation function (add! or rem!) and it updates a namespace atom holding the lens boxes.
The add! and rem! functions both mutate the boxes atom. Both have to check if a lens exists or not with a has-lens? predicate. The key of an element in the boxes map is the lens number and the value is a vector holding the label/focal length pair. I didn’t matter to the output but I added a check in rem! to remove a key completely if it was removing the last lens.
The last function focusing-power calculates the power for a specified box number. It multiplies the position and focal lengths with the box number (incremented) and adds all the values.
It was a bit lazy to use an atom here but I decided it was simpler than carrying the boxes map through all the functions. If I was going to refactor, I’d probably implement run-cmd as a multi-method and dispatch on first. I’d also refactor to centralize the atom mutation more.
When I started this thing and after I finished the puzzle on Day 1, I didn’t realize that there was a part 2. I figured they were trying to lure me in with a simple, one-part problem so I never went back and checked going forward until now. This one had some trickiness to it.
It seemed the easiest way forward was to just replace all the digit words with their numeric values for each line. The problem is that if you have oneight, that replaces differently depending on which replace you do first (1 or 8).
Again, the easiest way forward was just to identify all the combinations where the last letter of one word was the same as the first of another. There are 8 of them.
What to replace them with though? Should eightwo become 8wo, eigh2, or 82. Since we have to map across the string both ways, the last option is the right pick.